Private RAG vs. Gemini Shootout (NIST 800-53 Edition)


I've been using the "free" version of Gemini included with my ChromeBook plus for a few months but recently decided to upgrade to Advanced and testing with documents in my Google Drive and within Google Docs. The advanced version also gives you better image generation capabilities. In the past I'd ingested NIST 800-53 into PrivateGPT on my Mac M3 with mixed results and though I'd try again on my ASUS Nvidia 3060 I added to my son's old gaming PC this past week, where I had Ollama.
Local Hardware Setup
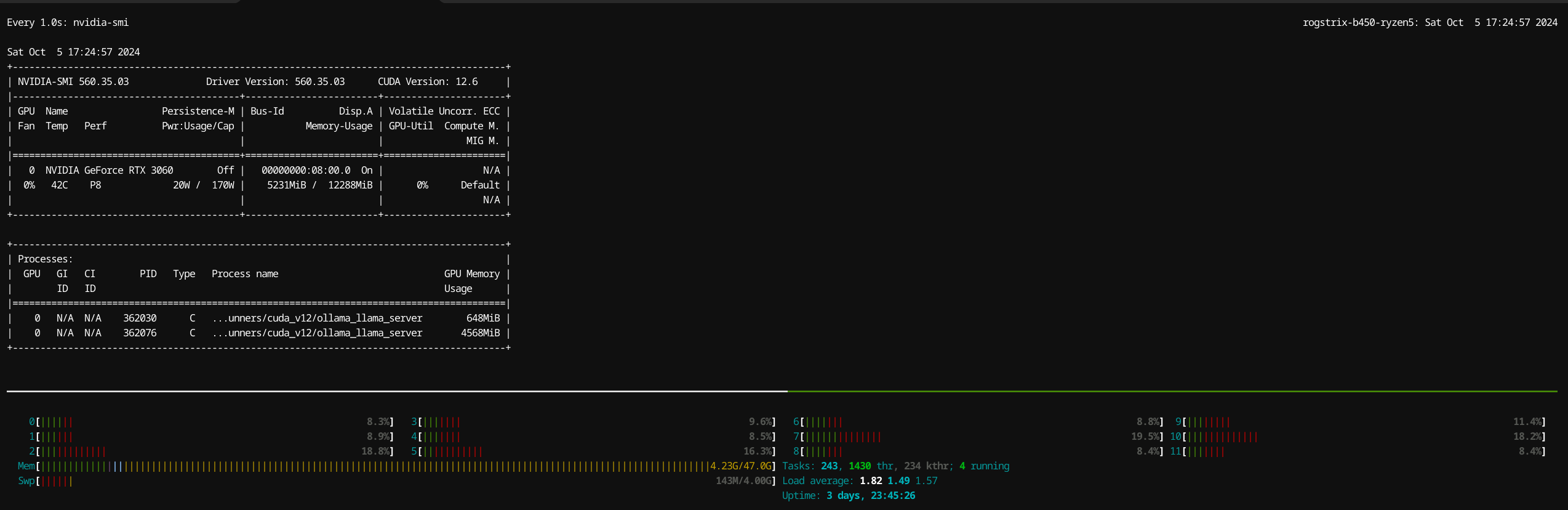
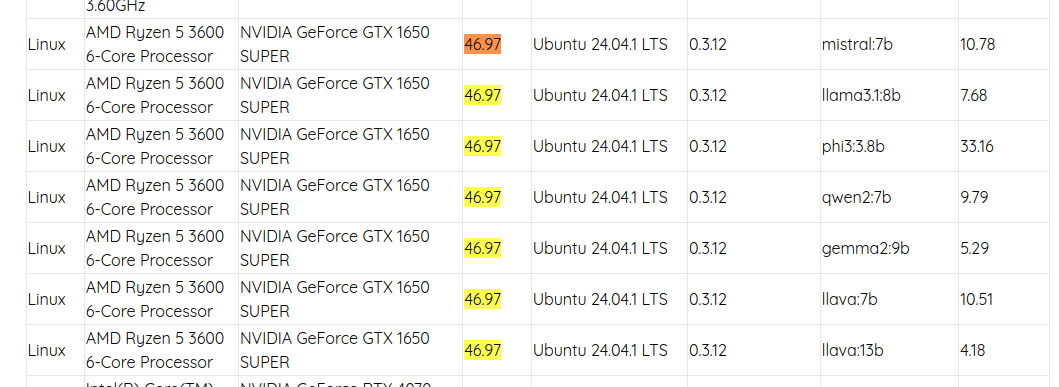
The stats above were generated by LLM Benchmark
Private RAG Configuration
Ollama 0.3.12
With the exception of having Ollama listening on 0.0.0.0 I used a default install of the latest Ollama with the CUDA 12 drivers that get installed with the shell script
root@rogstrix-b450-ryzen5:/etc/systemd/system/ollama.service.d# cat override.conf
[Service]
Environment="OLLAMA_HOST=0.0.0.0"
I used the following model for llama3.2
$ ollama show llama3.2:latest
Model
architecture llama
parameters 3.2B
context length 131072
embedding length 3072
quantization Q4_K_M PrivateGPT 0.6.2 (Llama 3.2 + Qdrant + Nomic)
Python is a blessing and curse for Development, but PrivateGPT is the easiest of the local RAG tools that I've found to install. It is on my list to get H2oGPT working with Ollama but it is a little trickier, so I put it off.
Since I'm running Ubuntu 24.04 (which uses Python 3.12) I had to install Python 3.11 with uv in a virtual environment I created. I tried to make PrivateGPT run with uv, but ended up sticking with Poetry and once I installed the right Python version it worked with no issue. By default
ubuntu@privatgpt:~/private-gpt-0.6.2/.venv$ cat pyvenv.cfg
home = /home/ubuntu/.local/share/uv/python/cpython-3.11.6-linux-x86_64-gnu/bin
implementation = CPython
uv = 0.4.18
version_info = 3.11.6
include-system-site-packages = false
prompt = private-gpt-0.6.2server:
env_name: ${APP_ENV:ollama}
llm:
mode: ollama
max_new_tokens: 512
context_window: 3900
temperature: 0.1 #The temperature of the model. Increasing the temperature will make the model answer more creatively. A value of 0.1 would be more factual. (Default: 0.1)
embedding:
mode: ollama
ollama:
llm_model: llama3.2
embedding_model: nomic-embed-text
api_base: http://100.115.28.90:11434
embedding_api_base: http://100.115.28.90:11434 # change if your embedding model runs on another ollama
keep_alive: 5m
tfs_z: 1.0 # Tail free sampling is used to reduce the impact of less probable tokens from the output. A higher value (e.g., 2.0) will reduce the impact more, while a value of 1.0 disables this setting.
top_k: 40 # Reduces the probability of generating nonsense. A higher value (e.g. 100) will give more diverse answers, while a lower value (e.g. 10) will be more conservative. (Default: 40)
top_p: 0.9 # Works together with top-k. A higher value (e.g., 0.95) will lead to more diverse text, while a lower value (e.g., 0.5) will generate more focused and conservative text. (Default: 0.9)
repeat_last_n: 64 # Sets how far back for the model to look back to prevent repetition. (Default: 64, 0 = disabled, -1 = num_ctx)
repeat_penalty: 1.2 # Sets how strongly to penalize repetitions. A higher value (e.g., 1.5) will penalize repetitions more strongly, while a lower value (e.g., 0.9) will be more lenient. (Default: 1.1)
request_timeout: 120.0 # Time elapsed until ollama times out the request. Default is 120s. Format is float.
vectorstore:
database: qdrant
qdrant:
path: local_data/private_gpt/qdrant
AnythingLLM (Llama 3.2 + LanceDB + Anything LLM Embedder)
AnythingLLM Desktop is distributed as an AppImage which installed on an Ubuntu 24.40 desktop without a GPU knowing I would point at a remote Ollama server over my tailnet given it is on a different wireless network.
I configured Ollama at the Ryzen PI describe above.
Vector store after ingesting the NIST standard.
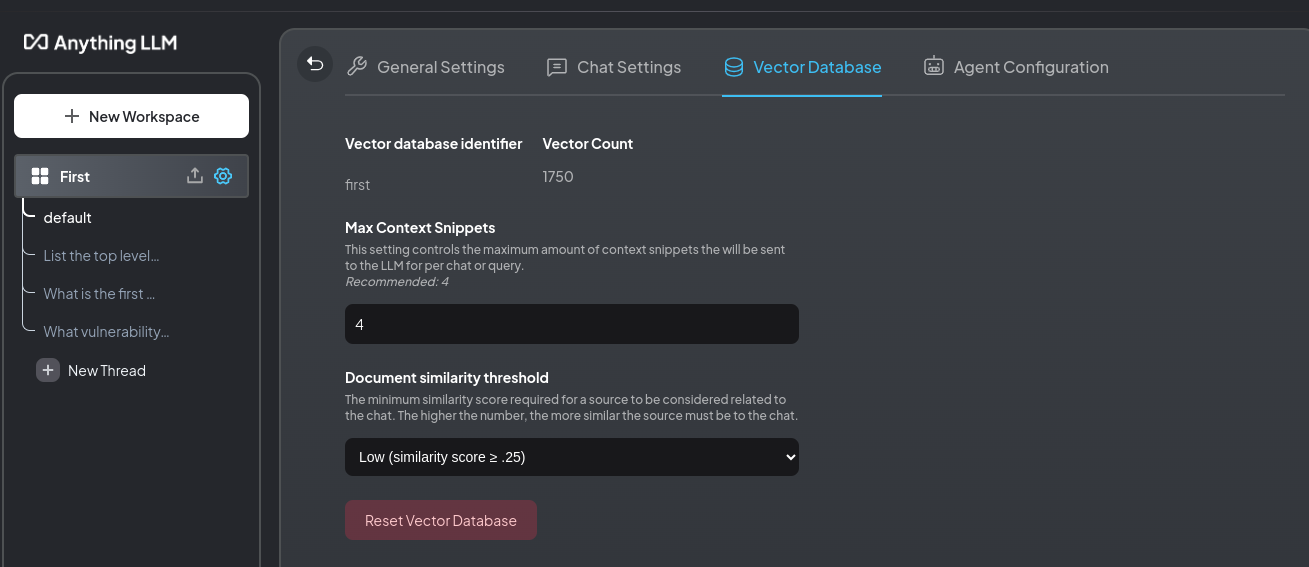
This is the first time I've used LanceDB
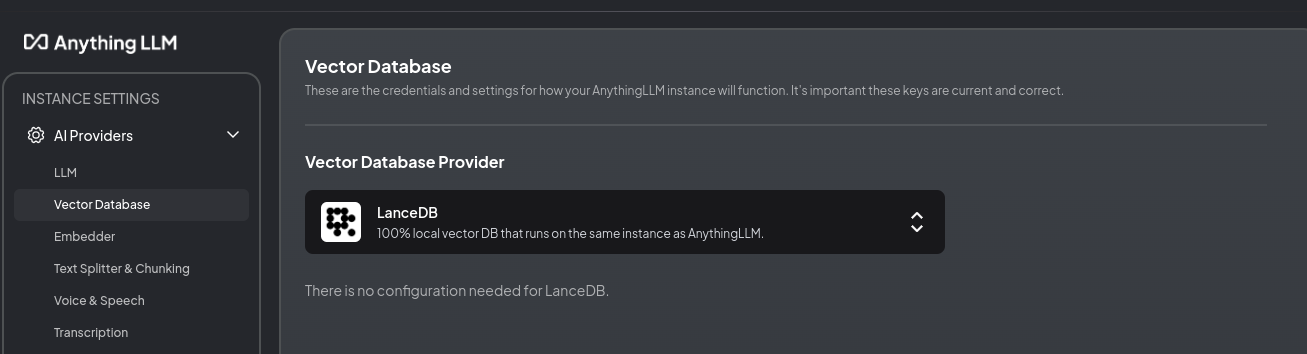
Anything LLM is based on MiniLM (a CPU model, which I assume is far less capable than Nomic.
Document Ingestion
Of course on Gemini (ingested from Google Drive or added to the Gemini chat window on my ChromeBook Plus) had no issues with ingestion of the nearly 6 MB NIST standard. Private GPT was the slowest taking at least 30-45 minutes to ingest the document, but it at least shows progress bar to know it was doing something. I left to go grab lunch and it was done when it came back. The initial estimate was 46 seconds but it went way over and about 600MB of GPU VRAM was used during the embedding process. There was minimal CPU usage on the PrivateGPT VM or the Baremetal PC hosting Ollama. AnythingLLM took about 4-5 minutes to ingest, but didn't indicate how long it would take to ingest. As I discovered after the ingestion, AnythingLLM ingestions and embedding does not even use the GPU.
Listing the Top Control Families
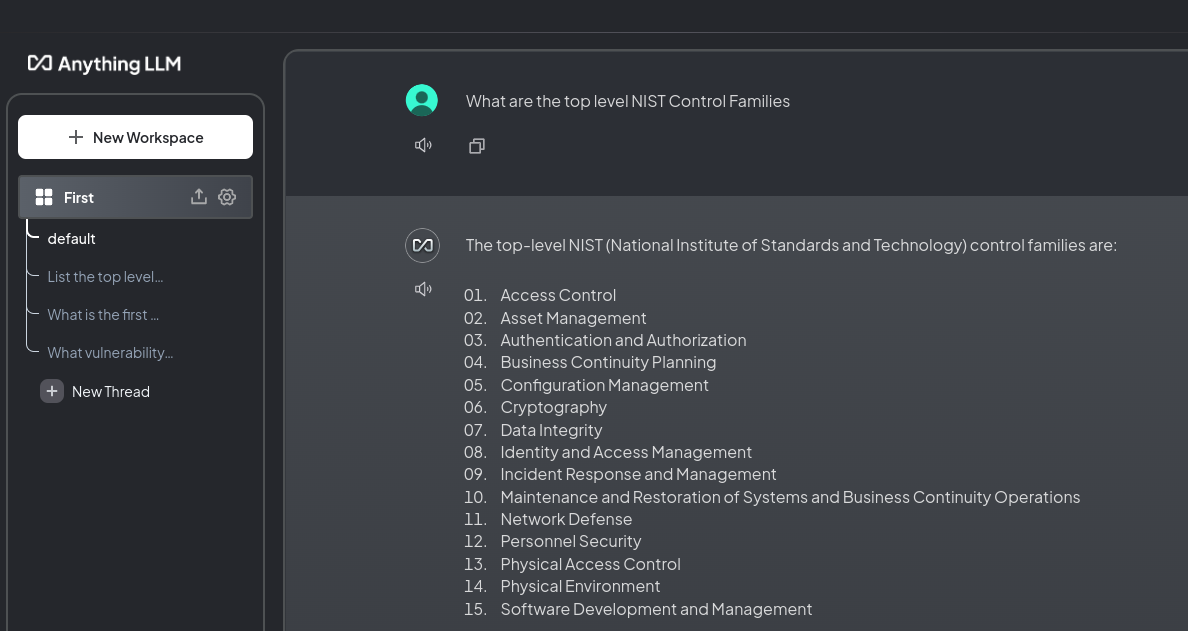
What are the top level NIST Control FamiliesGemini Advanced
Gemini was the only LLM to properly pull out the 20 controls families listed on Page 8 in the standard. None of the other tools could do this "simple" task.
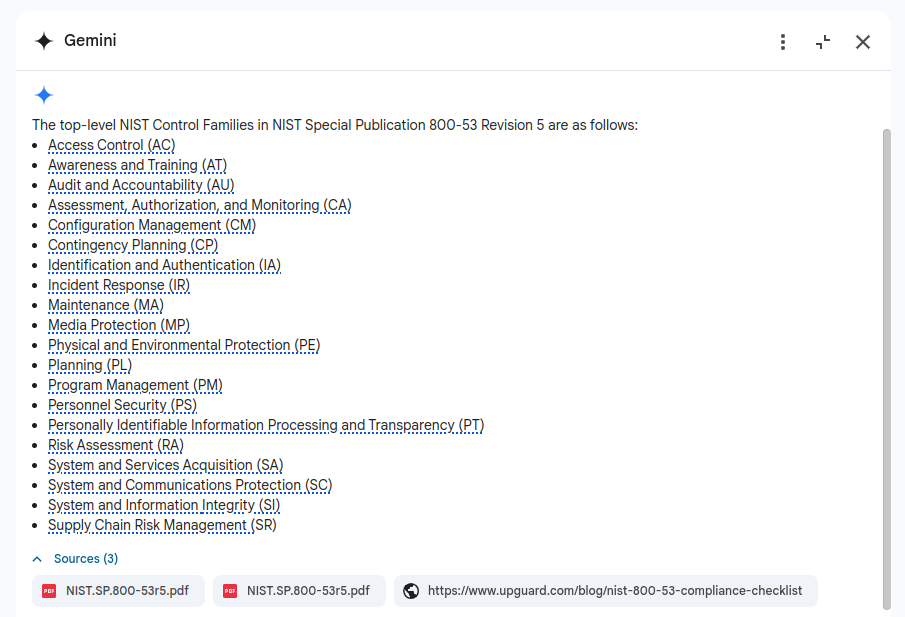
AnythingLLM
I got two different answers from AnythingLLM, the first with examples of controls.
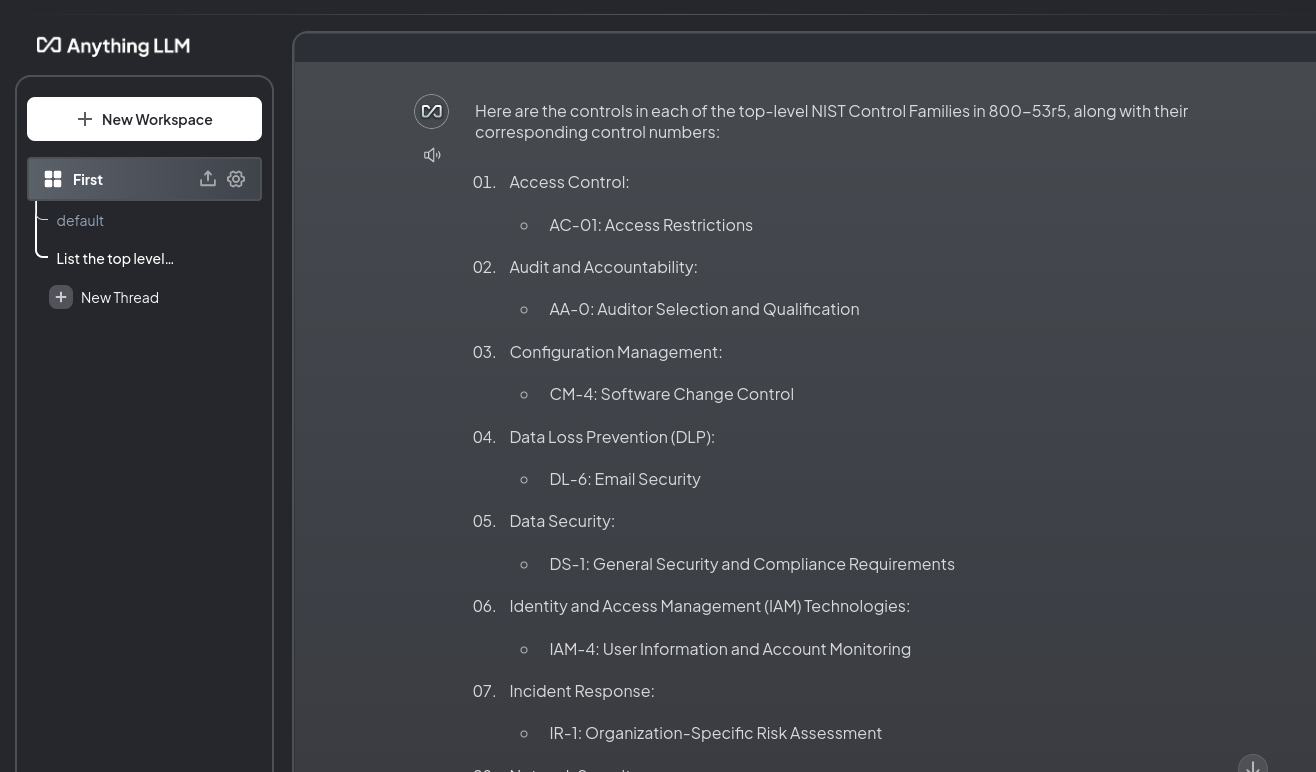
I created a new thread and it gave me these 15 controls only getting Access Control right.
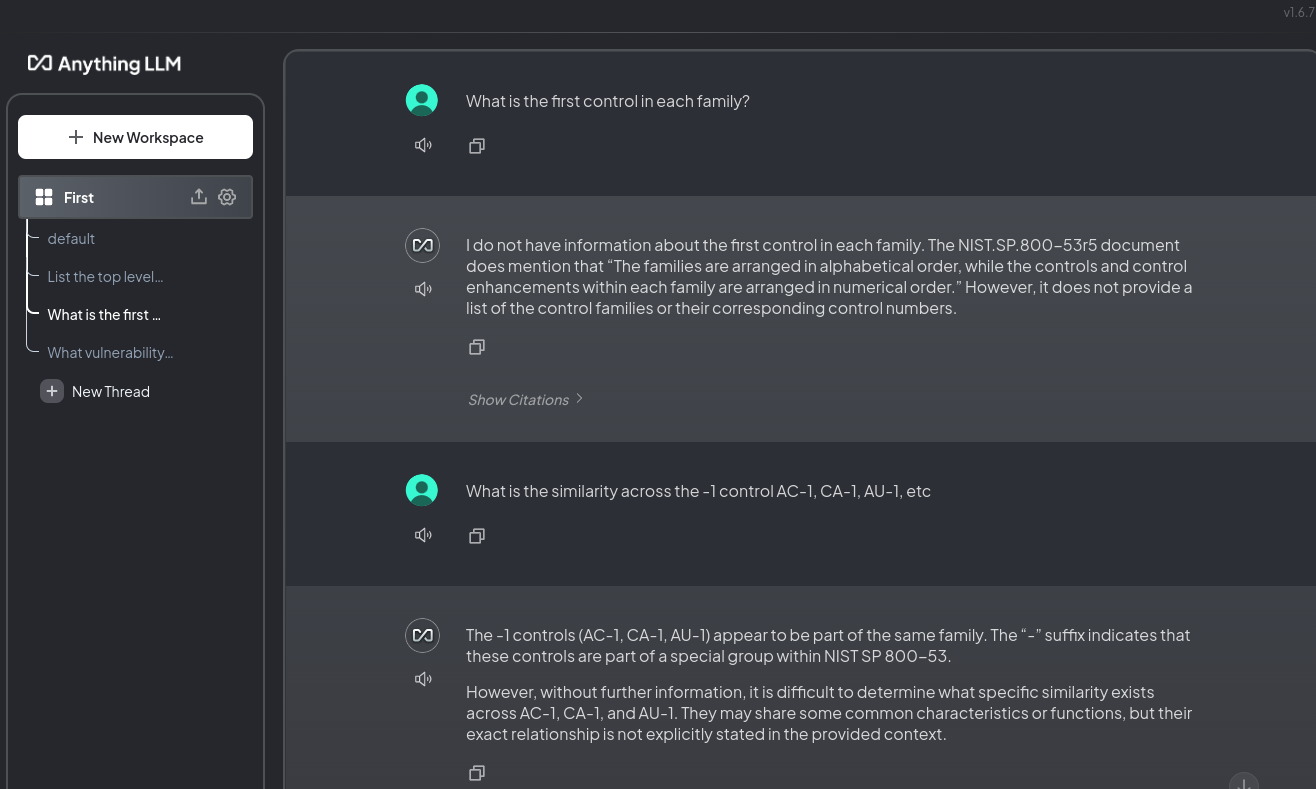
Understanding the (-1) Control in Each Family
Anyone that has has had to suffer through NIST 800-53 knows the first control is Policies and Procedures. I was curious if any of the LLM's would get this so I came up with this not great prompt to see how they would respond.
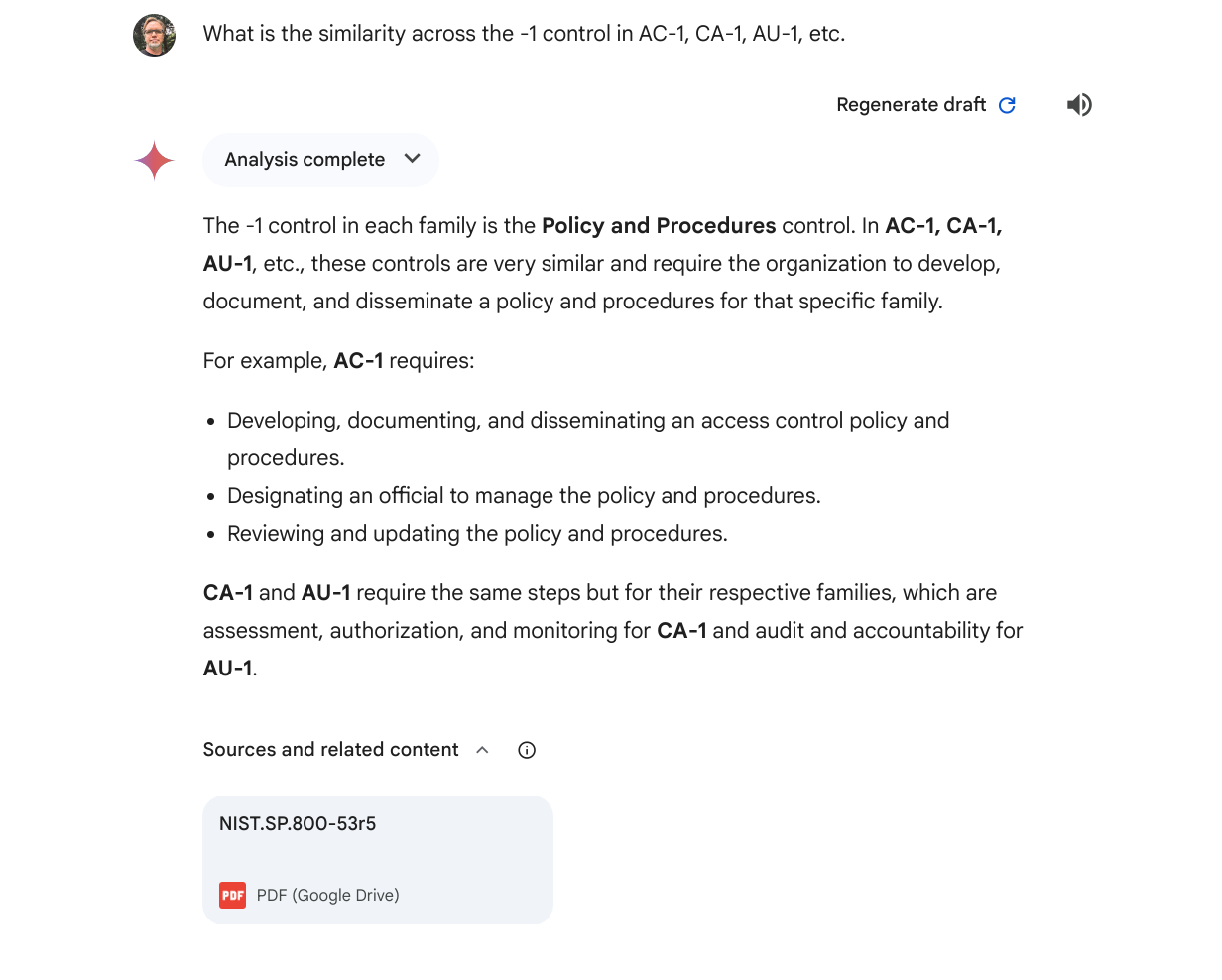
What is the similarity across the -1 control in AC-1, CA-1, AU-1, etc.Gemini Advanced
Gemini quickly and easily answered the prompt, getting the intent of my question.
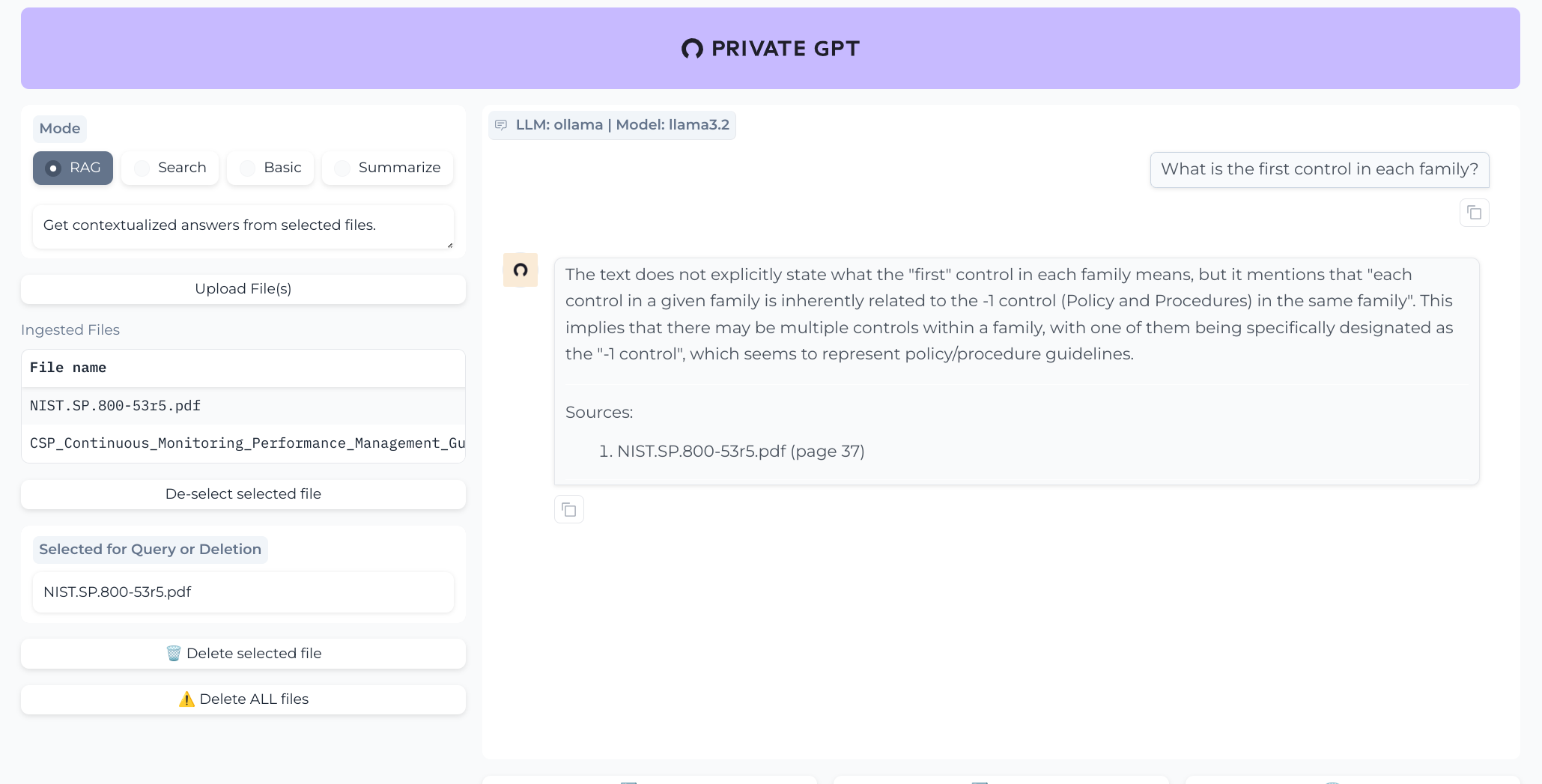
PrivateGPT
PrivateGPT also answers the question with an up-front caveat.
AnythingLLM
AnythingLLM really struggled to get the question.
Vulnerability Scanning
I crafted this intentionally vague prompt to see what the LLMs could understand about vulnerability scanning best practices.
What vulnerability scanning practices should be implemented to ensure most controls are covered?Gemini Advanced
Shockingly, I found Gemini's response was the most "word salad" among the three, although it started off well, but went downhill, not really understanding "organization-defined frequency" which is littered throughout NIST 800-53. However, it did mention CVSS and that scanners needed to updated and did mention classes of assets (meaning scan targets) in reasonable manner.
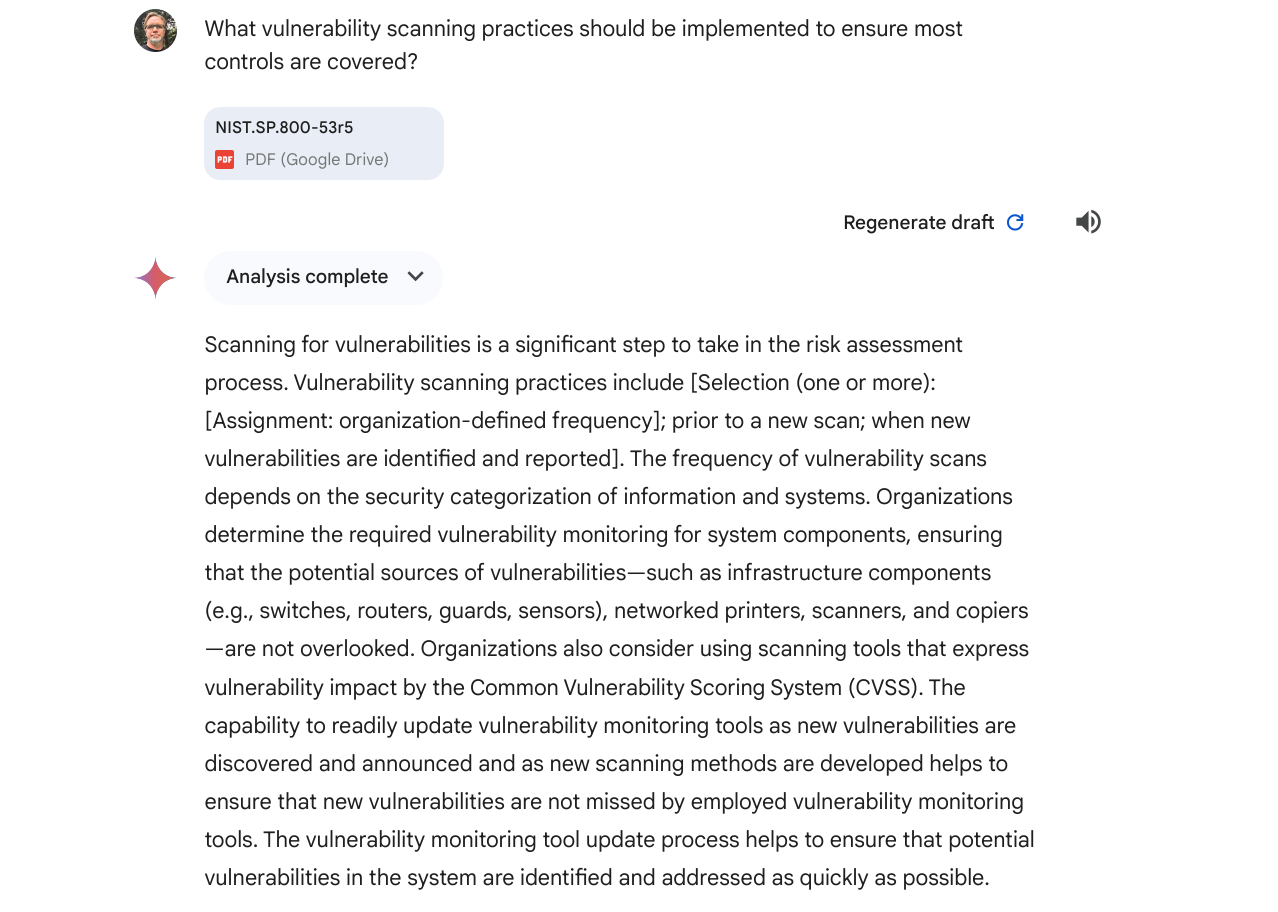
PrivateGPT
The markdown response with bold-faced, numbered list provided by llama3.2 + ChromaDB used by PrivateGPT was more help. It also didn't really understand "organization-defined frequency" but it did suggest monthly. It captured that different types of vulnerabilities exist (software flaws and improper configurations) as well as that the results need to be reviewed and communicated. Genius! It did pick up the idea of "scan coverage" but not "control coverage"
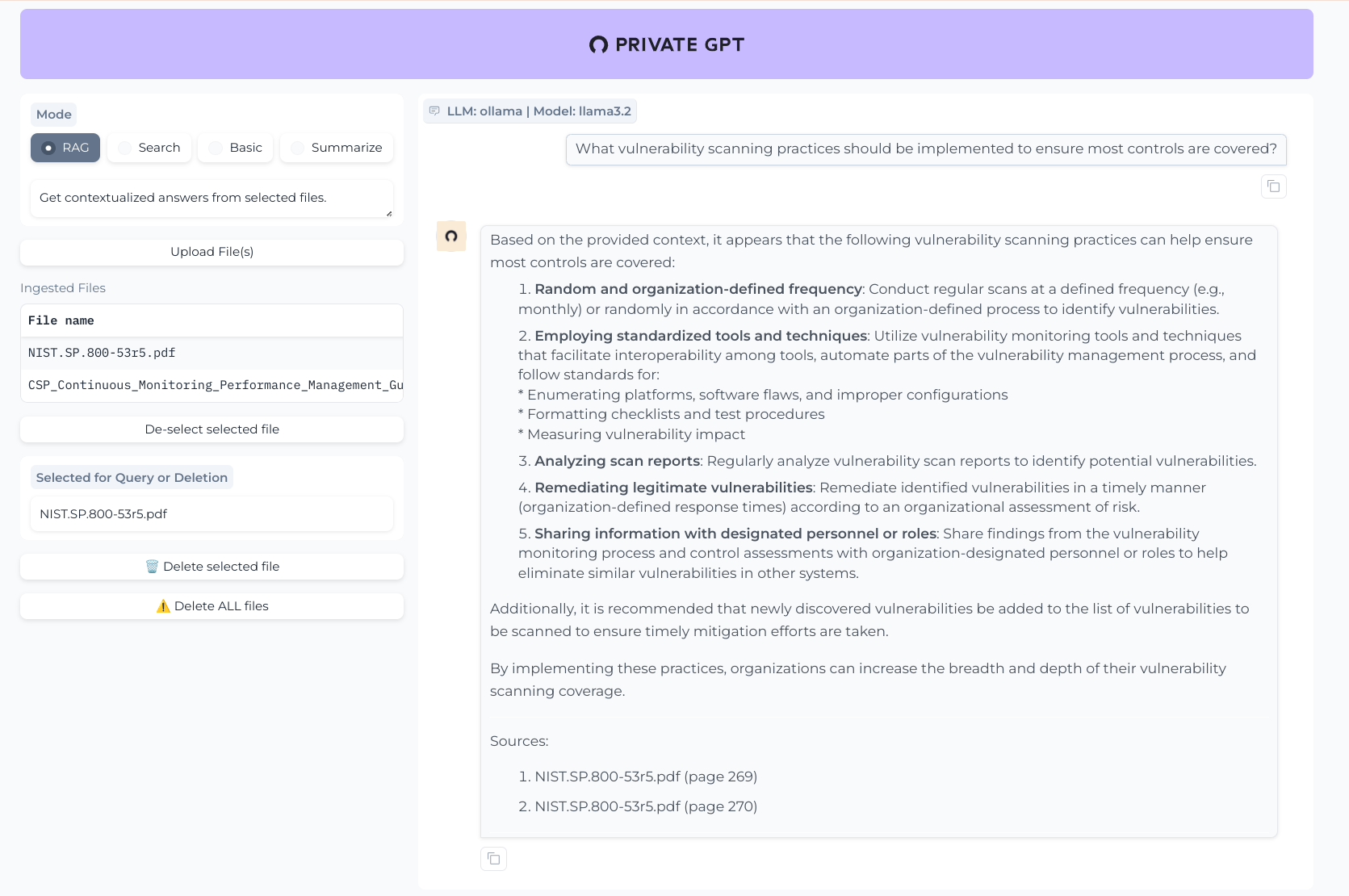
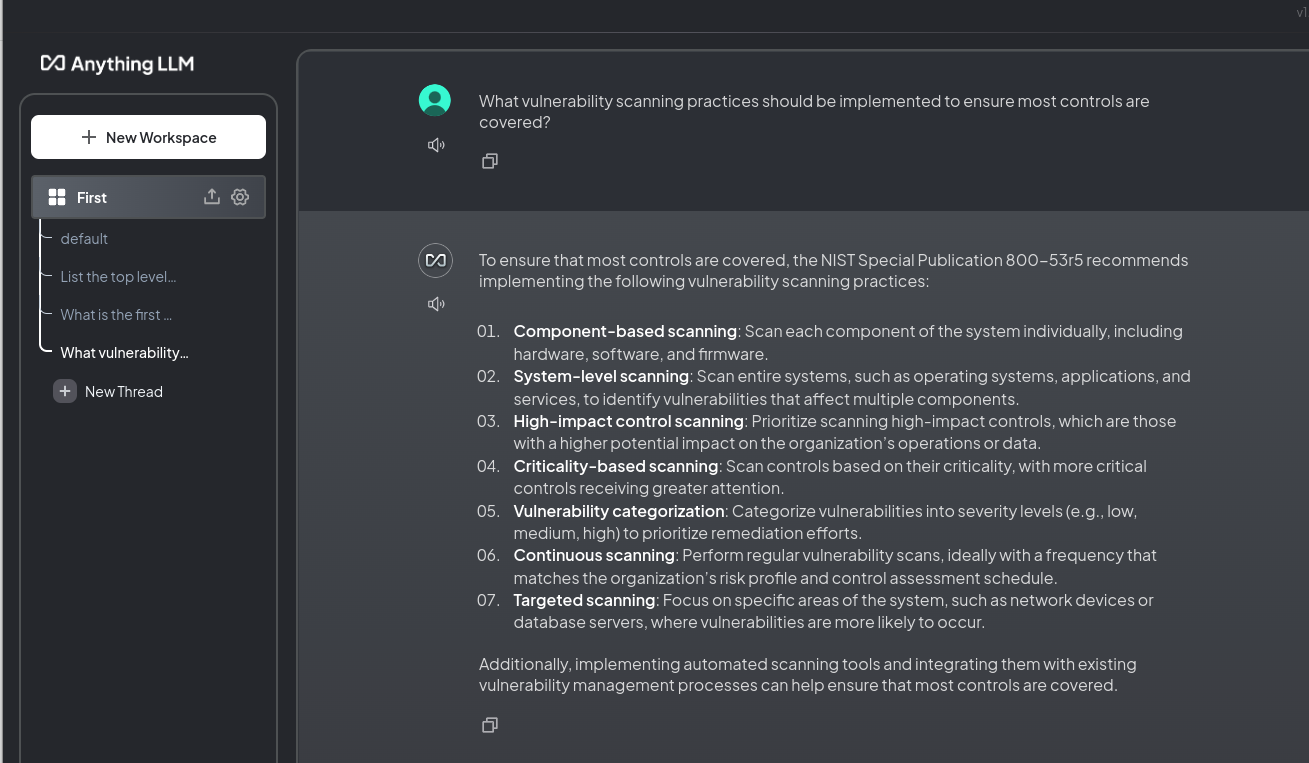
AnythingLLM
Like PrivateGPT, AnythingLLM returned a numbered bulleted list with short explanations. It did the best on this question compared to the others and I actually liked the fact that it capture system vs. component (even though it really doesn't understand what that means) as well as the idea that scanning should be continuous and that you should focus on most vulnerable systems. Given how poorly this configuration performed on the more basic questions, I surprised that it did this well.
TLDR: Pass on AnythingLLM and stick with python-llm for inference and native tools for RAG
I got better results using nomic with gemma2 but then I tried configuring AnythingLLM with OpenAI and the document uploading and embedding was just as problematic. The Workspace UX and threading interface is just janky and moving the embedded files between workspaces doesn't work reliably enough!
Given all the Plugins supported by Python-LLM I'll stick with that. It is much easier to just pick a different model for your query, and obviously allows you to directly pass commands (or cat files) to the llm through the shell.
$ llm models
OpenAI Chat: gpt-3.5-turbo (aliases: 3.5, chatgpt)
OpenAI Chat: gpt-3.5-turbo-16k (aliases: chatgpt-16k, 3.5-16k)
OpenAI Chat: gpt-4 (aliases: 4, gpt4)
OpenAI Chat: gpt-4-32k (aliases: 4-32k)
OpenAI Chat: gpt-4-1106-preview
OpenAI Chat: gpt-4-0125-preview
OpenAI Chat: gpt-4-turbo-2024-04-09
OpenAI Chat: gpt-4-turbo (aliases: gpt-4-turbo-preview, 4-turbo, 4t)
OpenAI Chat: gpt-4o (aliases: 4o)
OpenAI Chat: gpt-4o-mini (aliases: 4o-mini)
OpenAI Chat: o1-preview
OpenAI Chat: o1-mini
OpenAI Completion: gpt-3.5-turbo-instruct (aliases: 3.5-instruct, chatgpt-instruct)
GeminiPro: gemini-pro
GeminiPro: gemini-1.5-pro-latest
GeminiPro: gemini-1.5-flash-latest
GeminiPro: gemini-1.5-pro-001
GeminiPro: gemini-1.5-flash-001
GeminiPro: gemini-1.5-pro-002
GeminiPro: gemini-1.5-flash-002
GeminiPro: gemini-1.5-flash-8b-latest
GeminiPro: gemini-1.5-flash-8b-001
Ollama: codegeex4:latest (aliases: codegeex4)
Ollama: hermes3:8b
Ollama: nemotron-mini:latest (aliases: nemotron-mini)
Ollama: nomic-embed-text:latest (aliases: nomic-embed-text)
Ollama: llama3.2:latest (aliases: llama3.2)
Ollama: llava:7b
Ollama: llava:13b
Ollama: llama3.1:8b (aliases: llama3.1:latest, llama3.1)
Ollama: mistral:7b (aliases: mistral:latest, mistral)
Ollama: gemma2:9b (aliases: gemma2:latest, gemma2)
Ollama: phi3:3.8b
Ollama: qwen2:7b
Ollama: gemma:2b
Ollama: qwen2.5:14b
Ollama: granite-code:8b
Ollama: qwen2.5-coder:latest (aliases: qwen2.5-coder)
Ollama: yi-coder:latest (aliases: yi-coder)
Ollama: qwen:4b
Ollama: codegemma:2b
Ollama: phi:latest (aliases: phi)
As for RAG (summarization and querying) for now, I'll stick with native tooling. Primarily with Gemini since I don't actually have a ChatGPT subscription. It looks like I can get Gemini Plus through my Google One subscription and I can get metered Gemini through Google AI Studio, so nice try AnythingLLM but I'm good!