Build a Low Cost Serverless Linux SIEM with Vector, S3, and ClickHouse (Local)

It has been over five years since I first used Vector, but only in the last several months have I started to take advantage of ClickHouse with S3 as I mentioned on LinkedIn last month.
I also recently stood up a website with Ghost CMS for a non-profit and wanted something cheap and easy (off box) to analyze Nginx and Linux logs.
Since I know that Vector automatically parsed nginx and journald and could easily log to S3 so I gave it a shot.
Create your S3 Bucket & IAM Keypair
Use my CloudFormation template to create the S3 Bucket and IAM credentials that you'll need to pass to Vector to be able to write JSON events to the bucket.
NOTE: Since CloudFormation outputs are unencrypted, I've gotten into a habit of writing the Key to a Parameter so you can delete it later.
S3UserAccessKey:
Type: AWS::IAM::AccessKey
Properties:
UserName: !Ref S3User
BasicParameter:
Type: AWS::SSM::Parameter
Properties:
Name: !Sub ${S3Bucket}-${S3UserAccessKey}
Value: !GetAtt S3UserAccessKey.SecretAccessKey
Type: String
Install Vector Set your Environment Variables
Install the latest vector using your method of choice. I use the APT install script and this as worked across ARM and Intel systems just fine.
You'll put these in /etc/default/vector so you can avoid putting in your
AWS_ACCESS_KEY_ID=AKIAXXX
AWS_SECRET_ACCESS_KEY=YYYYY
VECTOR_S3_BUCKET=my-log-bucket/etc/default/vector
Define your Bucket "Path Schema"
We'll start at the end focusing on what is most critical on how you will search logs with Clickhouse Local where the path matters.
We'll get into that later. Trust me. It matters.
sinks:
s3_bucket:
type: aws_s3
inputs:
- common
bucket: "${VECTOR_S3_BUCKET}"
key_prefix: "{{hostname}}/{{event_type}}/%D/"
region: "us-east-1"
compression: gzip
encoding:
codec: jsonThis will create a directory structure like this once we have all the event_type's defined. These are essentially your "tables."
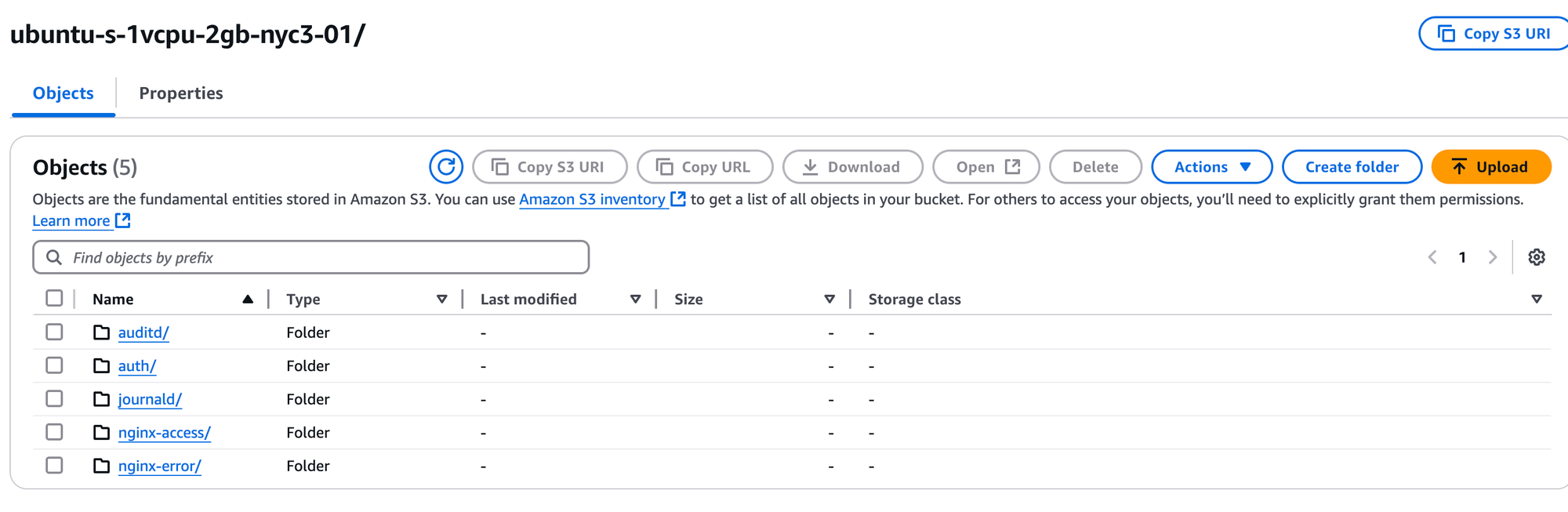
The %D will help populated the date structure so you can choose what to search overs, such as:
- asus-pn50/auditd/03/12/25/1741812841-d797e698-3302-4e63-a863-6f4292d04d16.log.gz
- opti3070/journald/03/04/25/1741798470-5f7b4bd9-abb4-42a6-9816-b82c4e7bbe96.log.gz
- ubuntu-s-1vcpu-2gb-nyc3-01/nginx-access/03/13/25/1741824471-f39b039f-be2f-4723-b74f-f5b7e3a495ec.log.gz
(This is where it is helpful to having hostname conventions!)
When you form your SELECT or DESCRIBE from clickhouse you'll be use wildcards to only retrieve a subset of objects.
Define your Data Sources
For basic file monitoring I use the file source and journald to avoid parsing syslog-style messages.
sources:
journald:
type: journald
nginx_access:
type: file
include:
- /var/log/nginx/access.log*
nginx_error:
type: file
include:
- /var/log/nginx/error.log*
auditd:
type: file
include:
- /var/log/audit/audit.log
auth_log:
type: file
include:
- /var/log/auth.logThis will create state files in /var/lib/vector like the following
root@ubuntu-s-1vcpu-2gb-nyc3-01:/var/lib/vector# ls
auditd auth_log journald nginx_access nginx_error var_log
root@ubuntu-s-1vcpu-2gb-nyc3-01:/var/lib/vector# ls -al
total 32
drwxr-xr-x 8 vector vector 4096 Mar 13 01:35 .
drwxr-xr-x 46 root root 4096 Mar 12 13:09 ..
drwxr-xr-x 2 vector vector 4096 Mar 13 01:35 auditd
drwxr-xr-x 2 vector vector 4096 Mar 13 01:35 auth_log
drwxr-xr-x 2 vector vector 4096 Mar 12 16:23 journald
drwxr-xr-x 2 vector vector 4096 Mar 13 01:37 nginx_access
drwxr-xr-x 2 vector vector 4096 Mar 13 01:35 nginx_errorAs I was getting the parsers (and the path structure) just right, I would stop vector, delete from the bucket, then delete whichever file and they would be re-ingested. S3 writes are not immediate and sometimes it does take up to 5-10 minutes during your initial ingestion.
Parse and Transform
See the end of the blog for the links to the full code, but transforms do the heavy lifting in VRL and I only used some very simple remaps to parse key value pairs in auditd as well as add the event_type field to each message. In the case of auditd_parse I did delete the "msg" field because it was not ingesting cleaning in ClickHouse, but I'll need to address that later because that field is the only part of the event that contains a timestamp.
transforms:
auditd_parse:
type: remap
inputs:
- auditd
source: |
. = parse_key_value!(.message)
.event_type = "auditd"
del(.msg)
.hostname = get_hostname!()
auth_parse:
type: remap
inputs:
- auth_log
source: |
. = parse_linux_authorization!(.message)
.event_type = "auth"
journald_parse:
type: remap
inputs:
- journald
source: |
.event_type = "journald"
common:
type: remap
inputs:
- auth_parse
- auditd_parse
- journald_parse
source: |
.hostname = get_hostname!()The common transform at the end allows me to add the common hostname field onto each message.
Parser Development & Testing
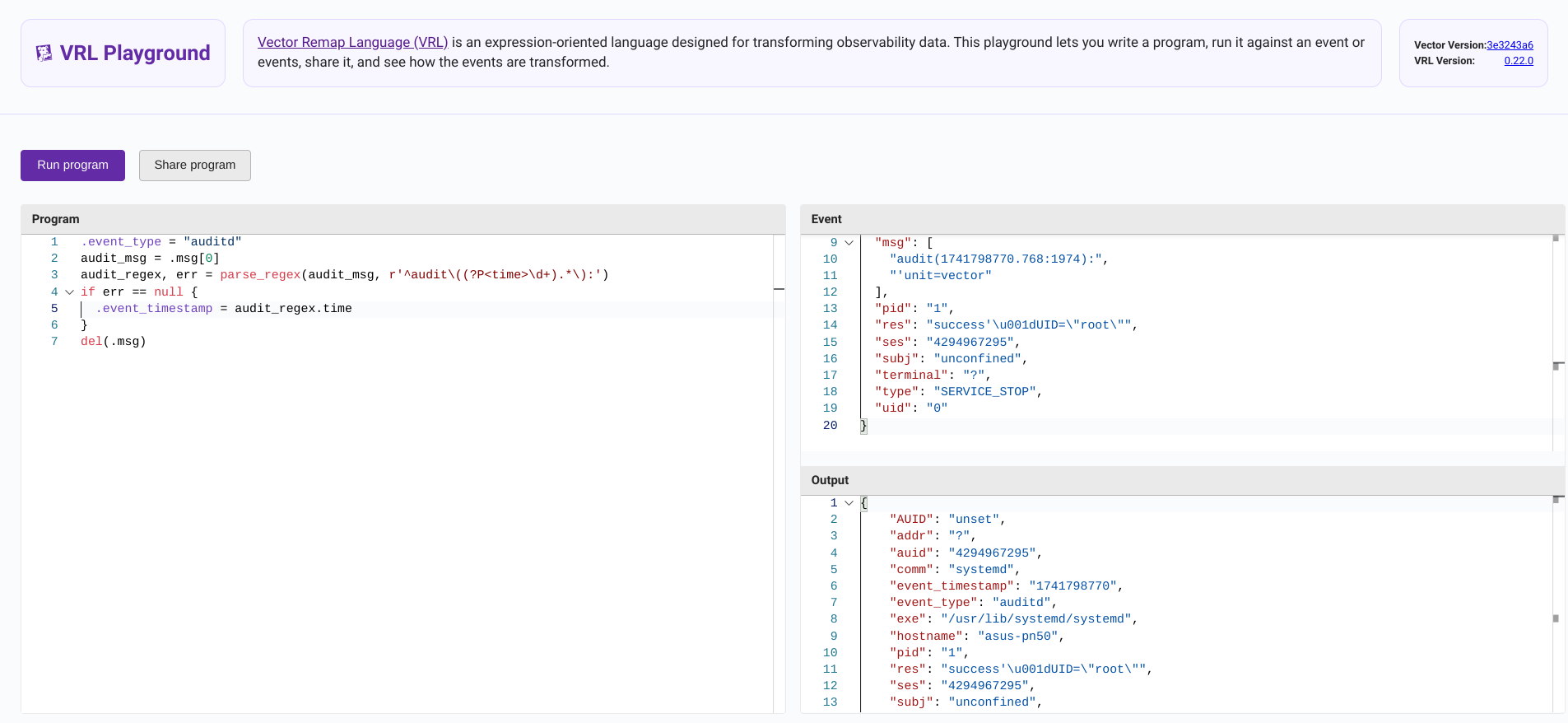
Although you can test your VRL on pipelines the best way to do this is either by running vector vrl with an input JSON stream and the code to show the output like this. See my vrl-devtest report scripts and sample data to test this out. This allows you to run across a larger dataset to ensure you are properly handling errors.
This is just the VRL code used by the remap.
.event_type = "auditd"
audit_msg = .msg[0]
audit_regex, err = parse_regex(audit_msg, r'^audit\((?P<time>\d+).*\):')
if err == null {
.event_timestamp = audit_regex.time
}
del(.msg)
.hostname = get_hostname!()You then execute with the following command.
vector vrl -i auditd.json -p auditd.vrl -o --print-warnings When developing the initial parser you can also use the VRL Playground to test your code but it will not include all the functions such as get_hostname()
LLMs were not very helpful for VRL code examples, but there are lots of GitHub projects so searching for parse_regex vector language:yaml in GitHub code search is the best way to find examples.
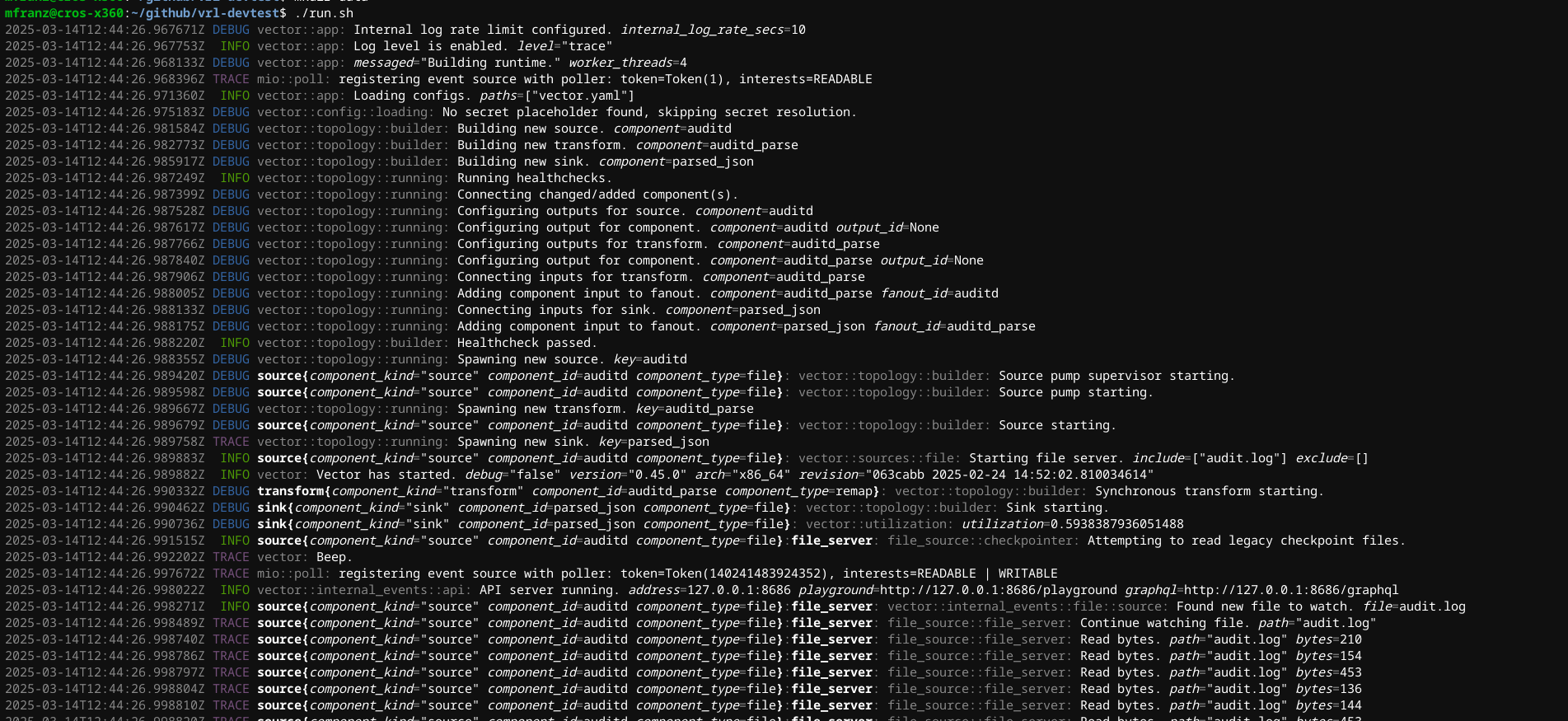
Before you wire up S3, it does make sense to test locally with just file sources and sinks. The run.sh is just a simple wrapper for vector -vv -c vector.yaml and clean.sh removes the watcher files that are created so you can rapidly retest.
Assessing the Data in S3
Assuming you've set your AWS Environment variables, ClickHouse will honor those.
SELECT DISTINCT event_type
FROM s3('https://bucket_name.s3.us-east-1.amazonaws.com/*/*/*/*/*/*.log.gz')
Query id: cd07ac4e-9640-414b-be84-459fc84b8c3d
┌─event_type─┐
1. │ auditd │
└────────────┘
┌─event_type─┐
2. │ auth │
└────────────┘
┌─event_type─┐
3. │ journald │
└────────────┘
3 rows in set. Elapsed: 57.546 sec. Processed 6.20 million rows, 162.91 MB (107.76 thousand rows/s., 2.83 MB/s.)
Peak memory usage: 1.33 GiB.Remember the path structure allows to you search only subset of the data, for example this counts the various event types in March 2025
SELECT
count(*) AS cnt,
event_type
FROM s3('https://bucket_name.s3.us-east-1.amazonaws.com/*/*/03/*/25/*.log.gz')
GROUP BY event_type
ORDER BY cnt ASC
Query id: d1de464f-b6f0-406e-9fbd-20a7dcf0f80c
┌─────cnt─┬─event_type─┐
1. │ 7717 │ auth │
2. │ 17697 │ auditd │
3. │ 2181709 │ journald │
└─────────┴────────────┘
3 rows in set. Elapsed: 28.226 sec. Processed 2.21 million rows, 58.29 MB (78.19 thousand rows/s., 2.07 MB/s.)
Peak memory usage: 1.33 GiB.Getting at the Schema
Simply use DESCRIBE to have ClickHouse infer the schema
DESCRIBE TABLE s3('https://bucket_name.s3.us-east-1.amazonaws.com/*/journald/*/*/*/*.log.gz')
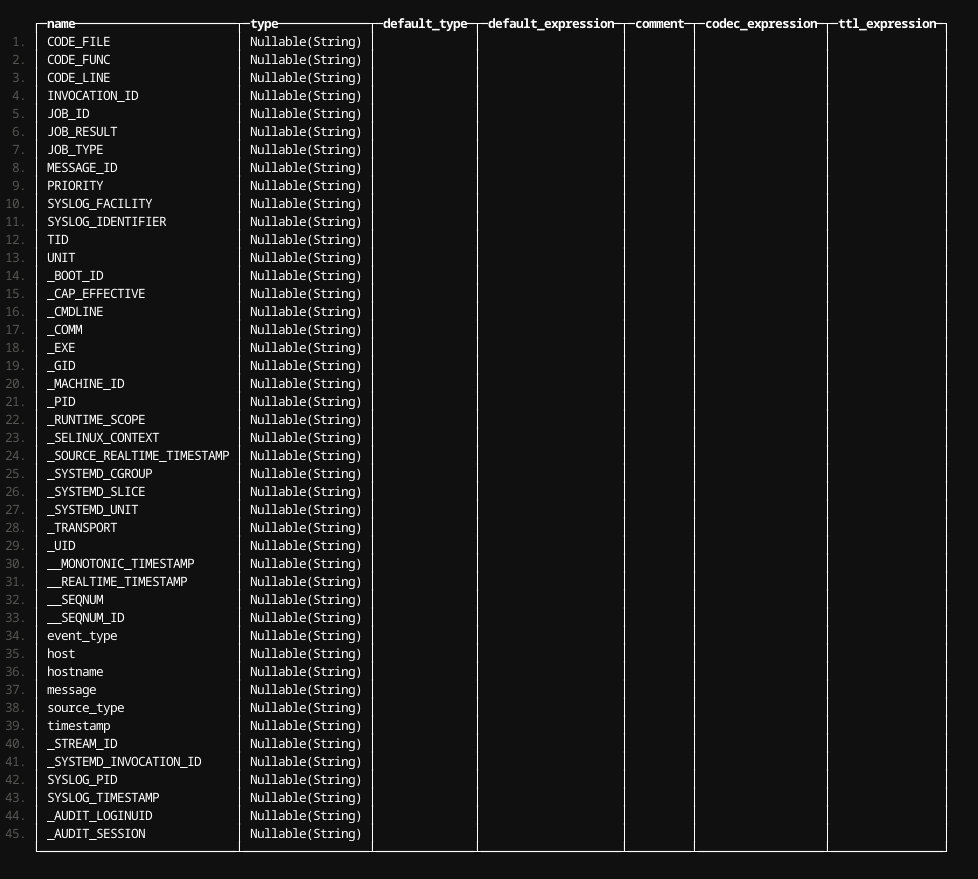
And for auditd
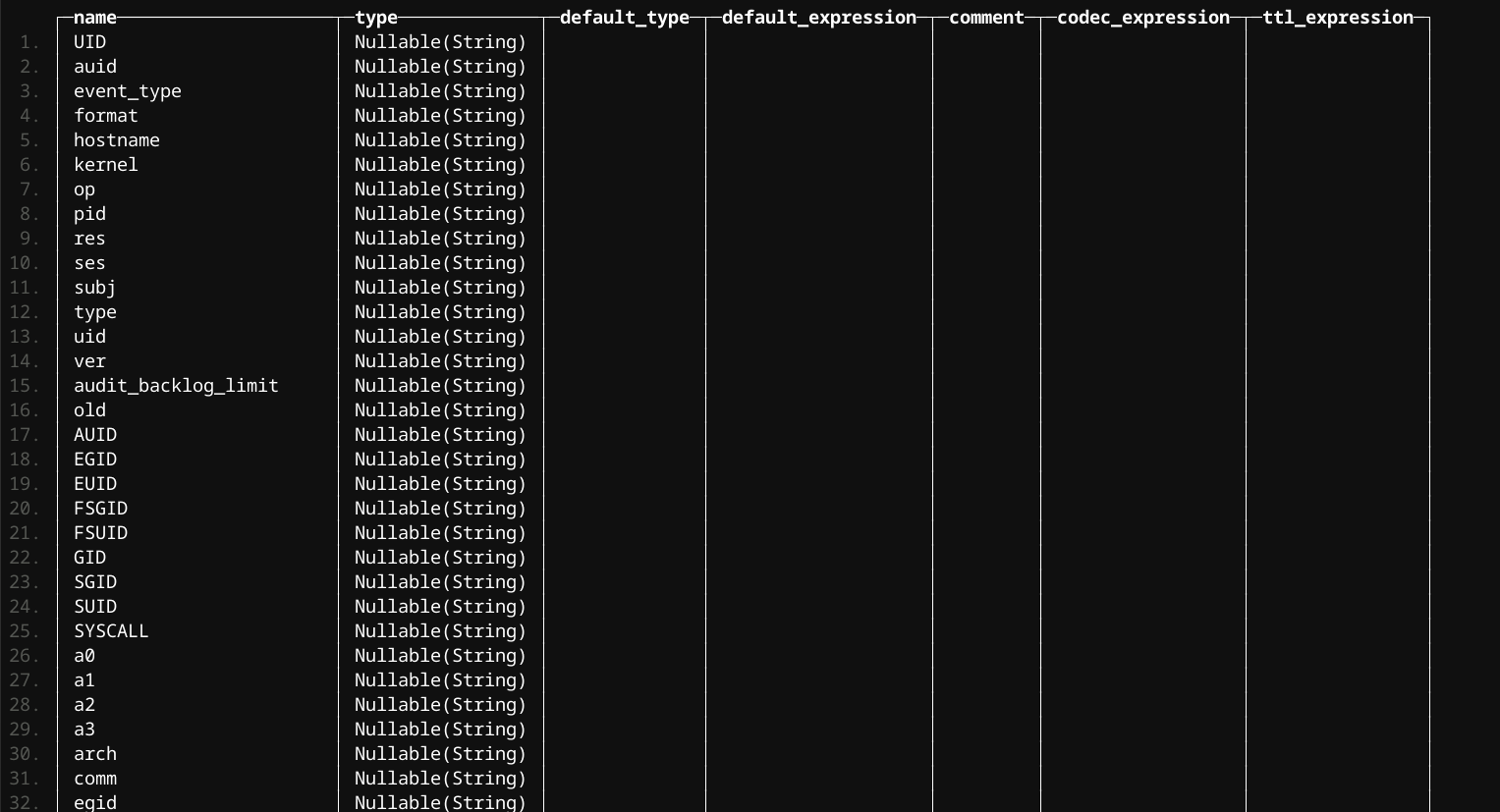
And auth which is pretty sparse in comparison.

Digging into the Data
Let's start with auth... Remember DISTINCT is your friend for starting to characterize.
SELECT DISTINCT (appname, hostname)
FROM s3('https://bucket_name.s3.us-east-1.amazonaws.com/*/auth/*/*/*/*.log.gz')
ORDER BY appname ASC
Query id: 0ad7a767-034d-4728-bfb7-731a0db313a0
┌─(appname, hostname)────────────────────────────┐
1. │ ('CRON','asus-pn50') │
2. │ ('CRON','franz-OptiPlex-7050') │
3. │ ('CRON','opti3070') │
4. │ ('chfn','opti3070') │
5. │ ('dbus-daemon','franz-OptiPlex-7050') │
6. │ ('gdm-password]','franz-OptiPlex-7050') │
7. │ ('gnome-keyring-daemon','franz-OptiPlex-7050') │
8. │ ('gpasswd','opti3070') │
9. │ ('groupadd','opti3070') │
10. │ ('passwd','opti3070') │
11. │ ('pkexec','franz-OptiPlex-7050') │
12. │ ('polkitd','opti3070') │
13. │ ('polkitd','asus-pn50') │
14. │ ('sshd','asus-pn50') │
15. │ ('sshd','opti3070') │
16. │ ('sshd','franz-OptiPlex-7050') │
17. │ ('sudo','opti3070') │
18. │ ('sudo','asus-pn50') │
19. │ ('sudo','franz-OptiPlex-7050') │
20. │ ('systemd-logind','asus-pn50') │
21. │ ('systemd-logind','opti3070') │
22. │ ('systemd-logind','franz-OptiPlex-7050') │
23. │ ('systemd-machined','asus-pn50') │
24. │ ('useradd','opti3070') │
25. │ ('userdel','opti3070') │
26. │ ('usermod','opti3070') │
└────────────────────────────────────────────────┘What we can already tell from just this table that
franz-OptiPlex-7050is the only system running Ubuntu desktop- Users were added and deleted on
opti3070
So pkexec was only run on one system let's take peek
SELECT (timestamp, message)
FROM s3('https://bucket.s3.us-east-1.amazonaws.com/*/auth/*/*/*/*.log.gz')
WHERE appname = 'pkexec'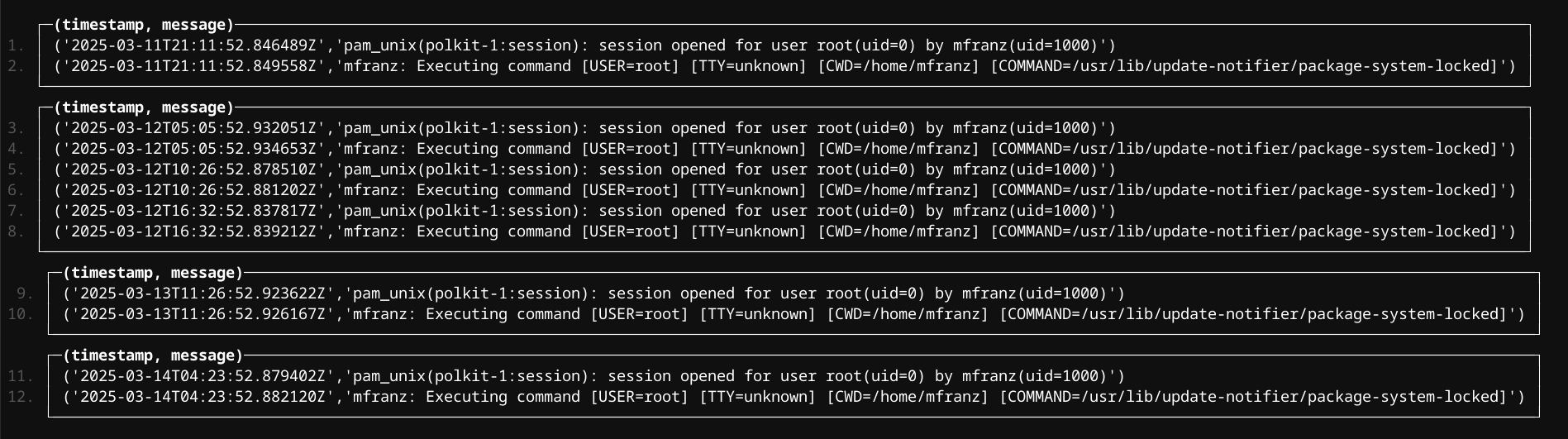
There is obviously a lot more you can do with the data depending on your SQL skills, but this shows you how to get started!
Putting it all together
data_dir: "/var/lib/vector"
api:
enabled: true
sources:
journald:
type: journald
auditd:
type: file
include:
- /var/log/audit/audit.log
auth_log:
type: file
include:
- /var/log/auth.log
transforms:
auditd_parse:
type: remap
inputs:
- auditd
source: |
. = parse_key_value!(.message)
.event_type = "auditd"
audit_msg = .msg[0]
audit_regex, err = parse_regex(audit_msg, r'^audit\((?P<time>\d+).*\):')
if err == null {
.event_timestamp = audit_regex.time
}
del(.msg)
.hostname = get_hostname!()
auth_parse:
type: remap
inputs:
- auth_log
source: |
. = parse_linux_authorization!(.message)
.event_type = "auth"
journald_parse:
type: remap
inputs:
- journald
source: |
.event_type = "journald"
common:
type: remap
inputs:
- auth_parse
- auditd_parse
- journald_parse
source: |
.hostname = get_hostname!()
sinks:
s3_bucket:
type: aws_s3
inputs:
- common
bucket: "${VECTOR_S3_BUCKET}"
key_prefix: "{{hostname}}/{{event_type}}/%D/"
region: "us-east-1"
compression: gzip
encoding:
codec: json